Engage NY Eureka Math Algebra 1 Module 2 End of Module Assessment Answer Key
Eureka Math Albegra 1 Module 2 End of Module Assessment Task Answer Key
Question 1.
A recent social survey asked 654 men and 813 women to indicate how many close friends they have to talk about important issues in their lives. Below are frequency tables of the responses.

a. The shape of the distribution of the number of close friends for the males is best characterized as
A. Skewed to the higher values (i.e., right or positively skewed).
B. Skewed to the lower values (i.e., left or negatively skewed).
C. Symmetric.
Answer:
A. Skewed to the higher values (i.e., right or positively skewed).
b. Calculate the median number of close friends for the females. Show your work.
Answer:
\(\frac{(813+1)}{2}\) = 407
201 + 146 = 347 + 155 = 502
407th observation falls in 2 columns
2 close friends
c. Do you expect the mean number of close friends for the females to be larger or smaller than the median you found in part (b), or do you expect them to be the same? Explain your choice.
Answer:
Mean should be larger than median because of skewedness.
d. Do you expect the mean number of close friends for the males to be larger or smaller than the mean number of close friends for the females, or do you expect them to be the same? Explain your choice.
Answer:
From 2 on, females have higher counts than males in every column. This shows that females tend to have more close friends. So, the male average is probably smaller than the female average.
Question 2.
The physician’s health study examined whether physicians who took aspirin were less likely to have heart attacks than those who took a placebo (fake) treatment. The table below shows their findings.

Based on the data in the table, what conclusions can be drawn about the association between taking aspirin and whether or not a heart attack occurred? Justify your conclusion using the given data.
Answer:
\(\frac{189}{11034}\) = 0.017 \(\frac{104}{11037}\) = 0.0094
The placebo group had higher proportion of heart attacks, although both numbers are pretty small.
Question 3.
Suppose 500 high school students are asked the following two questions:
→ What is the highest degree you plan to obtain? (check one)
→ High school degree
→ College (Bachelor’s degree)
→ Graduate school (e.g., Master’s degree or higher)
→ How many credit cards do you currently own? (check one)
→ None
→ One
→ More than one
Consider the data shown in the following frequency table.

Fill in the missing value in the cell in the table that is marked with a “?” so that the data would be consistent with no association between education aspiration and current number of credit cards for these students. Explain how you determined this value.
Answer:
\(\frac{?}{x}\) = \(\frac{y}{297}\frac{6}{z}\) = \(\frac{59}{500}\)
z = \(\frac{500 \times 6}{59}\) = 50.8 ≈ 51
500 – 51 – 297 = 152
\(\frac{?}{152}\)= \(\frac{59}{500}\)
So,? = 17.936 ≈ 18
Question 4.
Weather data were recorded for a sample of 25 American cities in one year. Variables measured included January high temperature (in degrees Fahrenheit), January low temperature (in degrees Fahrenheit), annual precipitation (in inches), and annual snow accumulation. The relationships for
three pairs of variables are shown in the graphs below (January Low Temperature—Graph A; Precipitation—Graph B; Annual Snow Accumulation—Graph C).
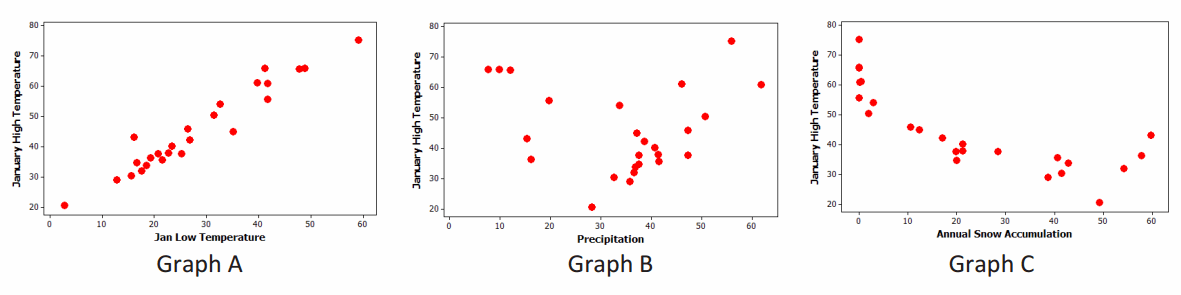
a. Which pair of variables will have a correlation coefficient closest to 0?
A. January high temperature and January low temperature
B. January high temperature and precipitation
C. January high temperature and annual snow accumulation
Explain your choice:
Answer:
B. January high temperature and precipitation
There is not much of a linear association but lots of scatter.
b. Which of the above scatter plots would be best described as a strong nonlinear relationship? Explain your choice.
Answer:
Graph C has a strong nonlinear relationship because it has a curved pattern, and the dots follow the pattern pretty closely.
c. Suppose we fit a least squares regression line to Graph A. Circle one word choice for each blank that best completes this sentence based on the equation:
If I compare a city with a January low temperature of 30°F and a city with a higher January low temperature, then the (1) January high temperature of the second city will (2) be (3).
(1) actual, predicted
(2) probably, definitely
(3) lower, higher, the same, equally likely to be higher or lower
Answer:

d. For the city with a January low temperature of 30°F, what do you predict for the annual snow accumulation? Explain how you are estimating this based on the three graphs above.
Answer:
The annual snow accumulation will be about 10 inches because January’s low of 30° F corresponds to a January high of about 50° F in Graph A, which matches with 10 inches in Graph C.
Question 5.
Suppose times (in minutes) to run one mile were recorded for a sample of 100 runners ages 16–66, and the following least squares regression line was found.
Predicted time in minutes to run one mile =5.35+0.25×(age)
a. Provide an interpretation in context for this slope coefficient.
Answer:
For every year older that a runner is, we predict the time to run one mile to increase by 0.25 seconds.
b. Explain what it would mean in the context of this study for a runner to have a negative residual.
Answer:

The runner was even faster (lower time) than we could have predicted for that age.
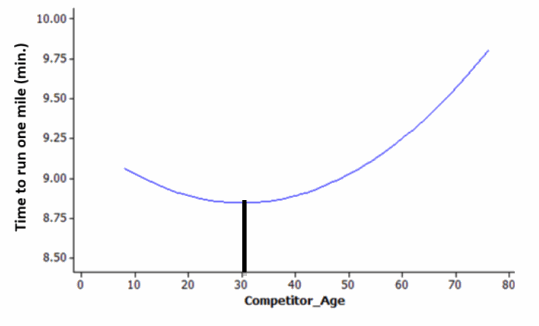
c. Suppose, instead, that someone suggests using the following curve to predict time to run one mile. Explain what this model implies about the relationship between running time and age and why that relationship might make sense in this context.
Answer:
This model implies that runners get faster (lower mile times) until around age 30 , when they start to slow down. In this context, the relationship might indicate that the younger runners had not trained as long as runners in their thirties, which would explain the decrease in times from age 10 to age 30 . Then, as runners’ ages continue to increase, their mile times also increase due to the decrease in muscle strength that comes with age.
d. Based on the results for these 100 runners, explain how you could decide whether the first model or the second model provides a better fit to the data.
Answer:
Look at the residuals and see which model (straight line or curve) provides a better match to the data.
e. The sum of the residuals is always equal to zero for the least squares regression line. Which of the following must also always be equal to zero?
A. The mean of the residuals
B. The median of the residuals
C. Both the mean and the median of the residuals
D. Neither the mean nor the median of the residuals
Answer:
A. The mean of the residuals